Time measurement
One of the reasons for writing concurrent programs is to optimize the execution time. An essential part of the optimization is measuring.
Has concurrent program better performance? Is the multithreaded version faster than the single threaded? How does performance scale if we use more threads? Measuring the execution time can answer such questions.
In this article, we will look at some built-in techniques for measuring time and benchmarking.
std::chrono
The standard way to measure time in C++ is to use the
<chrono> standard
library.
The library has several functions which returns current time. The most
appropriate function for measuring the time intervals is the
std::chrono::steady_clock. The
reason is that the time of this clock can not decrease as the time moves
forwards. The clock does not reset itself, therefore it is always monotonic.
Let’s say that we would like to measure the time needed to sum one million
elements of a vector. We can measure it with the function
std::chrono::steady_clock::now(),
which returns current value of the clock.
auto n = 1000000;
std::vector<int> vector(n, 1);
auto t1 = std::chrono::steady_clock::now();
auto sum = std::accumulate(vector.begin(), vector.end(), 0);
auto t2 = std::chrono::steady_clock::now();The std::chrono::duration_cast< time_t
>
takes a duration and converts it to the duration of the type
time_t. The duration time could be anything from nanoseconds
to hours.
using nano_s = std::chrono::nanoseconds;
using micro_s = std::chrono::microseconds;
using milli_s = std::chrono::milliseconds;
using seconds = std::chrono::seconds;
using minutes = std::chrono::minutes;
using hours = std::chrono::hours;With these types and the two times t1, t2,
we can calculate the duration in several units.
auto d_nano = std::chrono::duration_cast<nano_s>( t2 - t1 ).count();
auto d_micro = std::chrono::duration_cast<micro_s>( t2 - t1 ).count();
auto d_milli = std::chrono::duration_cast<milli_s>( t2 - t1 ).count();
auto d_s = std::chrono::duration_cast<seconds>( t2 - t1 ).count();
auto d_m = std::chrono::duration_cast<minutes>( t2 - t1 ).count();
auto d_h = std::chrono::duration_cast<hours>( t2 - t1 ).count();In my machine the printing
std::cout << "sum: " << sum << "\n"
<< "d_nano: " << d_nano << "\n"
<< "d_micro: " << d_micro << "\n"
<< "d_milli: " << d_milli << "\n"
<< "d_s: " << d_s << "\n"
<< "d_m: " << d_m << "\n"
<< "d_h: " << d_h << "\n"
<< std::endl;produces
sum: 1000000
d_nano: 451180
d_micro: 451
d_milli: 0
d_s: 0
d_m: 0
d_h: 0Simple benchmarking
Running the upper snippet of code several times will produce similar but a bit different results. This is completely normal. It is a consequence of operations of the inner parts of the computer.
In order to get more accurate results, we should perform measurement several times. Then, we should compute the average/mean of all measurements and the standard deviation. The standard deviation tells us how are the measurements spread around the mean value. If the standard deviation is small, all measurements are spread around the mean value. Otherwise, if the deviation is big, then the measurements are spread over a wide area around the mean.
There are people who recommend to throw away certain number of the initial measurements, because the initial ones might be less accurate then the following. Naively, we can imagine this effect as warming up the computer to its working temperature :-).
Let’s write a simple class, which will benchmark the execution time of a function call. The class declaration is:
template <typename TimeT = std::chrono::microseconds>
class Benchmark
{
public:
Benchmark(int num_iterations=100, int throw_away=0)
template <typename Fun, typename... Args>
std::vector< typename std::result_of< Fun(Args...) >::type >
benchmark(Fun fun, Args&&... args)
typename TimeT::rep mean() const
typename TimeT::rep standard_deviation() const
private:
...private data members and member functions...
};The class has a template parameter TimeT which determines the
measuring units.
The constructor accepts two arguments:
num_iterations- the number of measurements,throw_away- the number of measurements, which will be thrown away.
The Benchmark::benchmark accepts a function
fun and all of its arguments args. The member function measures the execution time of the input function (num_iterations +
throw_away) times.
The Benchmark::benchmark returns
the results of each execution of the function. There are two reasons for
returning the results.
- If we are benchmarking concurrent function, we can check if the function returns correct results. If the results are different, we might have a data race.
- When we return results, the compiler can not optimize away the function call.
If the syntax of the Benchmark::benchmark declaration is not
familiar to you, look at Variadic number of
arguments and Return type -
Part 1.
Additional public member functions are mean() and
standard_deviation(). They are accesors to the average (mean)
and standard deviation of all time measurements.
You can look at the entire source code of the class here.
Simple example
Let’s use the class for benchmarking std::accumulate. We
expect that the execution time increases linearly with respect to the number of
elements.
The source code is available below.
int main()
{
auto n = 1000000;
for (auto numEl = n; numEl != 11 * n; numEl += n)
{
Benchmark<> benchmark;
std::vector<int> vector(numEl, 1);
using Iterator = decltype(vector.begin());
auto results = benchmark.benchmark(std::accumulate< Iterator, int>,
vector.begin(), vector.end(), 0);
std::cout << "#elements: " << std::setw(9) << numEl << " "
<< " mean: " << std::setw(8) << benchmark.mean()
<< " st. dev: : " << std::setw(8)
<< benchmark.standard_deviation()
<< std::endl;
}
return 0;
}The main function loops over a different number of elements. The body of the
loop constructs the std::vector and benchmarks the
std::accumulate on the vector. In each iteration, the loop
prints the number of elements, the mean and the standard deviation of all
measurements.
The output of the program is:
#elements: 1000000 mean: 341 variance: 50
#elements: 2000000 mean: 652 variance: 60
#elements: 3000000 mean: 784 variance: 99
#elements: 4000000 mean: 928 variance: 91
#elements: 5000000 mean: 1144 variance: 93
#elements: 6000000 mean: 1395 variance: 102
#elements: 7000000 mean: 1641 variance: 129
#elements: 8000000 mean: 1843 variance: 109
#elements: 9000000 mean: 2093 variance: 117
#elements: 10000000 mean: 2316 variance: 143We can also visualize the output with a graph.
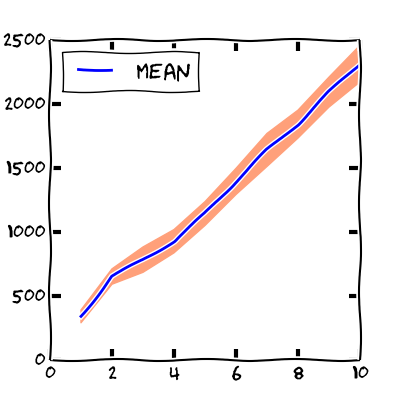
The x-coordinate represents the number of elements of the vector (in millions) and the y-coordinate shows the microseconds.
The blue line marks the mean of all time measurements. The pink area around the
mean indicates the region between mean - standard_deviation
and mean + standard_deviation. We see that the mean grows
linearly with respect to the number of elements. When increasing the number of
elements also the standard deviation increases.
Summary
We learned the basics of measuring the execution time.