OpenMP: Monte Carlo method for Pi
In the previous article we studied a
sequential Monte Carlo algorithm for approximating Pi (π).
In this article we briefly repeat the idea of the sequential algorithm. Then, we parallelize the sequential version with the help of OpenMP.
The sequential algorithm
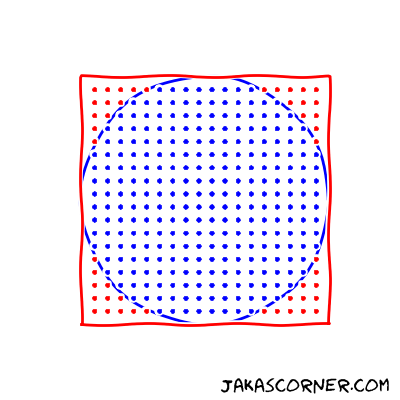
A Monte Carlo algorithm for approximating π
uniformly generates the points in the square [-1, 1] x [-1
1]. Then it counts the points which lie in the inside of the unit
circle.
An approximation of π is then computed by the following formula:

For more details about the formula look in the previous article.
The source code for the approximation algorithm is
double approximatePi(const int numSamples)
{
UniformDistribution distribution;
int counter = 0;
for (int s = 0; s != numSamples; s++)
{
auto x = distribution.sample();
auto y = distribution.sample();
if (x * x + y * y < 1)
{
counter++;
}
}
return 4.0 * counter / numSamples;
}It uses UniformDistribution to generate samples in
[-1, 1]. Then it counts the number of points in the inside of
the circle and computes an approximation of π by the
approximation formula.
Parallelization with OpenMP
The task is to parallelize the approximation algorithm with the help of OpenMP.
Looking at the function approximatePi, we might be tempted to
simply parallelize the for loop in the function with #pragma omp
parallel for. But unfortunately, this approach has some problems. It
introduces data races in the program.
The reasons for the data races are the variables distribution
and counter. They are updated by different iterations. If we
would parallelize the for loop, then the variables might be updated
by different threads at the same time.
Note that the distribution is updated in every iteration,
because the sampling updates the internal state of the procedure which generates
the random samples.
Since a simple parallelization of the approximatePi is not
possible, we slightly change the existing code.
Modifications
Our strategy is to divide the sampling into chunks. This strategy introduces two nested loops
- an outer loop over the chunks and
- an inner loop over the samples for each chunk.
The code for the outer loop is presented below
double parallelPi()
{
const int numTotalSamples = 1000000000;
int numChunks = 8;
int chunk = N / numChunks;
int counter = 0;
for (int i = 0; i < numChunks; i++)
{
counter += samplesInsideCircle(chunk);
}
return approxPi = 4.0 * counter / numTotalSamples;
}The function parallelPi divides the number of total samples
into eight chunks. The chunk variable holds the number of
samples for each chunk. Then the function loops over each chunk. In the for
loop, the function samplesInsideCircle generates samples and
counts the number of samples in the inside of the unit circle. In the end, the
parallelPi computes an approximation of the
π with the help of the known formula.
The missing piece is the function samplesInsideCircle. It is
presented below.
int samplesInsideCircle(const int numSamples)
{
UniformDistribution distribution;
int counter = 0;
for (int s = 0; s != numSamples; s++)
{
auto x = distribution.sample();
auto y = distribution.sample();;
if (x * x + y * y < 1)
{
counter++;
}
}
return counter;
}This function is very similar to the approximatePi. The
samplesInsideCircle generates numSamples
uniform samples and counts how many of them are in the inside of the circle.
Parallelization
Now, we are ready for a parallelization of the algorithm. We choose to parallelize the for loop over the chunks, since it is the outer for loop.
In this for loop
for (int i = 0; i < numChunks; i++)
{
counter += samplesInsideCircle(chunk);
}we have three shared variables: numChunks,
counter and chunk. We do not modify the
numChunks and chunk. They are read-only
variables. Therefore, this is not a problem. On the other hand, we modify the
counter. We must deal with the problem of data races for this
variable.
Before we continue, let us remember the sequential version of the program. There
we have problems (data races) with two variables:
distribution and counter. The
counter is still problematic but we do not have a problem
with the distribution. We avoided this problem by having a
different distribution for each chunk. With other words, the
sequential version initializes one object of
UniformDistribution and the parallel version initializes
numChunks objects of UniformDistribution.
Now, we continue with the problem of counter.
for (int i = 0; i < numChunks; i++)
{
counter += samplesInsideCircle(chunk);
}OpenMP has a special clause of the loop construct which solves this kind of
problems. This is the reduction clause which can specify a
reduction. An example of a reduction is
sum = a0 + a1 + a2 + a3 + a4 + a5 + a6 + a7 + a8 + a9Here, + is the operation which reduces a0,
a1, …, a9 into the
sum.
The reduction clause requires two things to specify a reduction
- the reduction operation and
- the variable, which will hold the result of the reduction.
In the for loop, counter is the variable, which will hold the
result and + is the reduction operation. The loop construct
then looks like
#pragma omp parallel for shared(numChunks, chunk) reduction(+:counter)
for (int i = 0; i < numChunks; i++)
{
counter += samplesInsideCircle(chunk);
}This loop construct correctly parallelizes the for loop. OpenMP increments the
shared variable counter without introducing a data race.
Example
We run the sequential and parallel versions of the Monte Carlo algorithm for
approximating π. We measure the execution time of the both
versions. The source code is available
here.
$ ./ompMonteCarloPi
Sequential version:
number of samples: 1000000000
real Pi: 3.141592653589...
approx.: 3.141582136
Time: 20017 milliseconds.
Parallel version:
number of samples: 1000000000
real Pi: 3.141592653589...
approx.: 3.141563188
Time: 3643 milliseconds.We can see that the execution time of the parallel version (3.6 seconds) is lower than the execution time of the sequential version (20 seconds). Both results are accurate up to four decimal places. I ran the computations on my machine which has 4 two-threaded cores.
In the next article, we will look in more detail at the reduction clause.
Summary
We parallelized a Monte Carlo method for approximating
π. We saw that the parallelization can decrease the execution
time.
Links:
Jaka’s Corner OpenMP series: