OpenMP: Single
Let us imagine the following problem. There are two companies with 25000 employees. Both companies have the same owner. She would like to know what are the salaries of all employees of each company.
Since we are programmers, we write a program which accumulates the salaries of all employees. It is a simple program, just two for loops which accumulate the salaries.
int main()
{
int salaries1 = 0;
int salaries2 = 0;
for (int employee = 0; employee < 25000; employee++)
{
salaries1 += fetchTheSalary(employee, Co::Company1);
}
std::cout << "Salaries1: " << salaries1 << std::endl;
for (int employee = 0; employee < 25000; employee++)
{
salaries2 += fetchTheSalary(employee, Co::Company2);
}
std::cout << "Salaries2: " << salaries2 << std::endl;
return 0;
}The program does its job, but it might take a lot of time to produce results. Fetching a salary might be an expensive operation. Therefore, we parallelize the program with OpenMP.
We use the reduction clause to parallelize the loops with OpenMP.
int salaries1 = 0;
int salaries2 = 0;
#pragma omp parallel shared(salaries1, salaries2)
{
#pragma omp for reduction(+: salaries1)
for (int employee = 0; employee < 25000; employee++)
{
salaries1 += fetchTheSalary(employee, Co::Company1);
}
std::cout << "Salaries1: " << salaries1 << std::endl;
#pragma omp for reduction(+: salaries2)
for (int employee = 0; employee < 25000; employee++)
{
salaries2 += fetchTheSalary(employee, Co::Company2);
}
std::cout << "Salaries2: " << salaries2 << std::endl;
}The program is faster than before, but it has data races. When OpenMP uses four threads for parallelization of the program, its output looks like this:
Salaries1: Salaries1: 1362004000
Salaries1: 1362004000
1362004000
Salaries1: 1362004000
Salaries2: Salaries2: Salaries2: 1464690000
1464690000
1464690000
Salaries2: 1464690000What happened?
OpenMP creates a team of threads with #pragma omp parallel
construct. Then, OpenMP parallelizes the first for loop. When the loop
terminates, the program prints the salaries inside the parallel
section. Therefore, each thread prints the salaries. The program prints them
four times, because the team of threads has four threads. There is also no
restriction which would prevent data races between the threads. Thus the
printing looks strange.
The rest of the program behaves similarly. OpenMP parallelizes the second for loop. When the loop finishes, the program again prints the salaries four times.
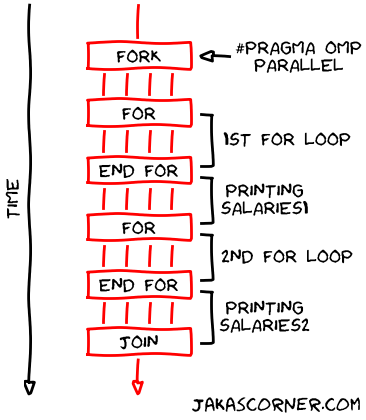
The following figure represents the timeline of the program. We can see four
lines in the printing salaries1 section and the printing
salaries2 sections. These four lines represent the four
threads.
Improvements
Now, we present three ways how to improve the previous program.
Version 1
The first idea is to use the parallel construct twice and then print the salaries outside the parallel regions.
#pragma omp parallel for reduction(+: salaries1)
for (int employee = 0; employee < 25000; employee++)
{
salaries1 += fetchTheSalary(employee, Co::Company1);
}
std::cout << "Salaries1: " << salaries1 << std::endl;
#pragma omp parallel for reduction(+: salaries2)
for (int employee = 0; employee < 25000; employee++)
{
salaries2 += fetchTheSalary(employee, Co::Company2);
}
std::cout << "Salaries2: " << salaries2 << std::endl;A disadvantage of this program is that it creates two teams of threads. The figure illustrates this fact.
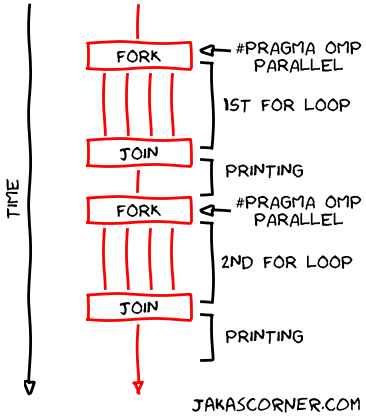
Creating two teams of threads (instead of one) is a disadvantage because of the overhead which is associated with a creation of a team. If we create two teams, we introduce the overhead twice.
However, the overhead might be negligible compared to the execution time of the loops. One should measure and verify if this truly is the case. If the overhead is negligible, than this version of the program is sufficient.
Version 2
The second idea is to first compute the salaries of the both companies in the parallel region and then print the salaries outside the parallel region.
#pragma omp parallel for reduction(+: salaries1, salaries2)
for (int employee = 0; employee < 25000; employee++)
{
salaries1 += fetchTheSalary(employee, Co::Company1);
salaries2 += fetchTheSalary(employee, Co::Company2);
}
std::cout << "Salaries1: " << salaries1 << "\n"
<< "Salaries2: " << salaries2 << std::endl;The following figure illustrates the timeline of this version of the program.
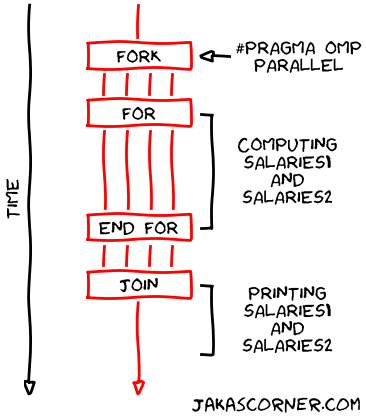
This solution is quite nice. It doesn’t have any data races and it uses less lines of code to express the solution.
A possible disadvantage of this version is that we have to wait for computations of all salaries to complete before we are able to see the results. The first version prints the results as soon as they are available. This version prints the results at the end of the execution.
Therefore it might happen that the first version prints
salaries1 after 5 seconds and salaries2
after 10 seconds from the start of the program. But this version might print
both salaries after 10 seconds. The first version gives us some information
earlier. This might (or might not) be important to us.
Version 3
The idea of the last version is to use the single construct.
#pragma omp parallel shared(salaries1, salaries2)
{
#pragma omp for reduction(+: salaries1)
for (int employee = 0; employee < 25000; employee++)
{
salaries1 += fetchTheSalary(employee, Co::Company1);
}
#pragma omp single
{
std::cout << "Salaries1: " << salaries1 << std::endl;
}
#pragma omp for reduction(+: salaries1)
for (int employee = 0; employee < 25000; employee++)
{
salaries2 += fetchTheSalary(employee, Co::Company2);
}
}
std::cout << "Salaries2: " << salaries2 << std::endl;The single construct is associated with a block of code.
#pragma omp single
{
// a block of code
}The block of code is executed by one thread only. All the other threads (from a team of threads) wait until the thread finishes executing the block.
This is exactly what we need in our program. We would like that the printing of
salaries1 is done by one thread only. The single construct
takes care of that.
The following figure presents the timeline of the program.
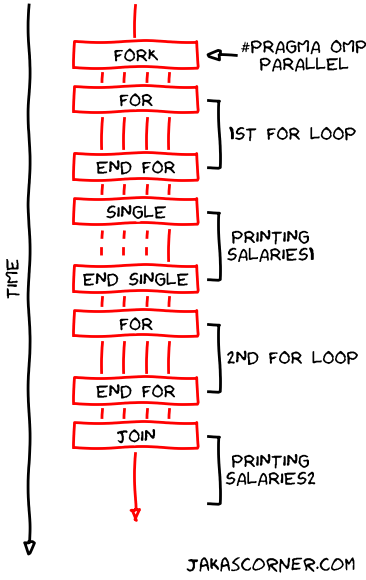
The single section in the figure illustrates the execution of the printing of
salaries1. This section contains four lines, which represent
four threads. Three lines are dashed and one line is not dashed. The undashed
line represents the thread which executes the single section. The dashed lines
represent the other threads which wait until the thread finishes executing the
single section.
This version has few advantages over the previous two versions. The last program creates only one team of threads, while the first version creates two teams of threads. This could be an advantage because creating a team of threads requires some overhead.
The last program prints the information as soon as it is available, while the second version prints the results at the end of the execution. This might (or might not) be relevant to us. However, the last program looks a bit complicated. It has more lines of code than the program in the second version.
Which version is the best?
Well, it depends on our requirements. If the execution time is important, one should measure the execution time of all three version and then choose the fastest one. If it is important to get partial results as soon as possible, one should choose version one or three. And if it is important that the code is clean, one should probably choose the second version.
Summary
We parallelized the program for accumulating salaries. The parallelization had a drawback. More precisely, the code which should be executed by only one thread was executed by a team of threads.
Therefore, we presented three approaches how to improve the misbehaved program. The third approach used the single construct. This construct takes care that the associated block of code is executed by one thread only. This is exactly what we need.
Links:
Jaka’s Corner OpenMP series: